이 기사
2022년 12월 7일부터 2022년 12월 18일까지 원티드에서 프리온보드 백엔드 챌린지에 참석하며 들은 이야기를 요약한 것입니다.

AWS RDS
관계형 데이터베이스 서비스
aws 사용 시 제한 없이만 사용할 수 있는 데이터베이스입니다.
db 운영 및 관리를 위한 편리한 서비스입니다.
nosql용 aws 서비스가 있습니다.
일반적으로 db를 운영하다 보면 db는 보통 관리가 너무 어려워 서비스에서 대부분의 문제가 발생한다고 할 수 있습니다.
서버가 잘 작동하지 않습니다. 서버를 쉽게 확장 및 축소할 수 있기 때문입니다.
rds는 관리하기 어렵습니다. 기본적으로 ec2와 같은 자동 스케일링은 없습니다. 바로 작동해야 합니다.
가로 범위와 세로 범위가 있습니다.
- 수평적 확장: 3개의 서버가 있고 3개의 서버 모두 CPU가 90%인 경우 수평적으로 증가합니다.
- 수직 확장: 서버의 사양을 높이는 개념입니다. 하나의 코어는 16GB의 메모리를 사용하는데, 2개의 코어로 메모리를 32GB로 늘리는 개념이다. 인스턴스를 따로 활성화하는 것이 아니라 기존 서버를 확장하는 방식이다.
rds는 높이 확장을 고려하여 작동해야 합니다.
주요 기능
- 장애 발생 시 스냅샷을 찍을 수 있는 기능. Auto Backup = 자동 백업 기간을 설정합니다. db=snapshot의 모든 데이터를 모델링하겠습니다.
- 다중 AZ : 가용 영역 : db가 손상되면 한 번에 손상되지 않도록 여러 곳에서 다중 동기화됩니다.
- CloudWatch 통합: 이는 aws의 별도 기능으로 생각하는 것이 좋습니다. DB 인스턴스 모니터링. 규약.
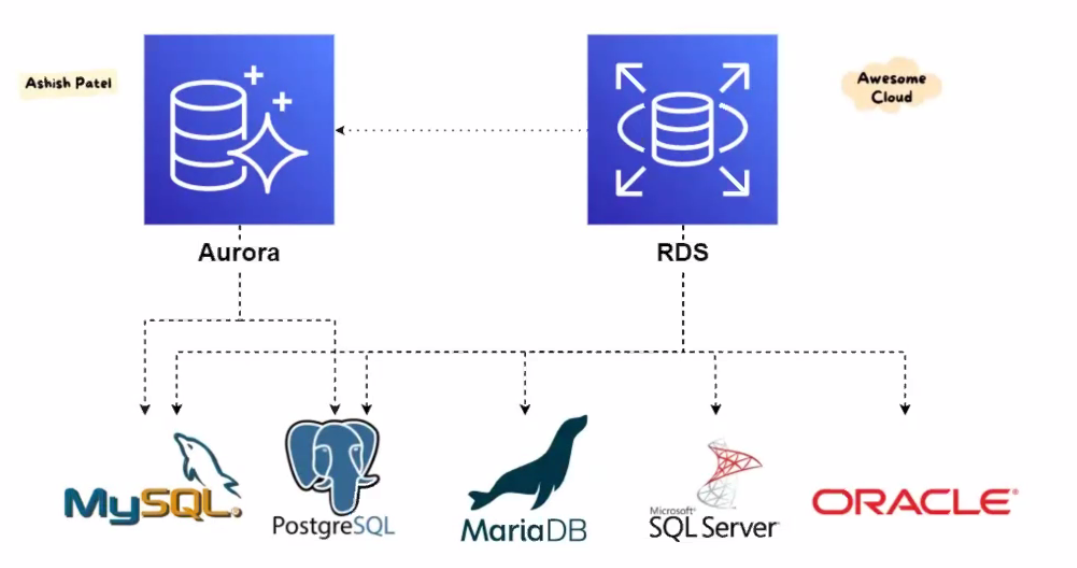
rds에도 오로라가 포함되어 있는데 사진에서는 오로라를 제외하여 설명하고 있습니다.
rds만 보면
총 5db가 지원됩니다.
- MySQL
- postgre-SQL
- 마리아드브
- 마이크로소프트SQL
- 신탁
AWS 오로라
자체 기술로 aws가 만든 새로운 형태의 DB
rds가 커피라면 오로라는 TOP(TOP) ㅎㅎ
어떻게 맞추셨나요?
- 가장 주목할만한 점은 SSD 드라이브를 기반으로 하므로 훨씬 더 빠릅니다.

r6g, 2xlarge: 인기 있는 인스턴스
- Auto-Scaling은 기본적으로 지원되며 사용량이 증가하면 좋습니다. 사용자가 없을 때 인스턴스를 접는 기능을 지원합니다.
- 서버리스 기능 지원: 일반 RDS에서 지원하지 않는 기능입니다.
- 서버리스 데이터베이스: 항상 켜져 있지 않고 AWS 측에서 요청을 처리하고 인스턴스를 관리하는 데이터베이스입니다.
- 프로덕션 데이터베이스에는 많은 사용자가 있고 항상 대기 중인 데이터베이스가 필요합니다. 일반적인 프로덕션 환경에서 Amazon Aurora는 서버리스 기능 없이 사용하고 테스트용 데이터베이스는 모든 인스턴스가 업로드되면 많이 사용되지 않으므로(내부적으로만 사용) Aurora 서버리스 DB를 사용합니다.
- 서버리스는 기본적으로 약간 느립니다. 정상적인 Aurora DB가 100ms이면 서버리스가 더 민감합니다.
- 서버리스가 아닌 데이터베이스가 더 빠릅니다.
오로라 대 RDS
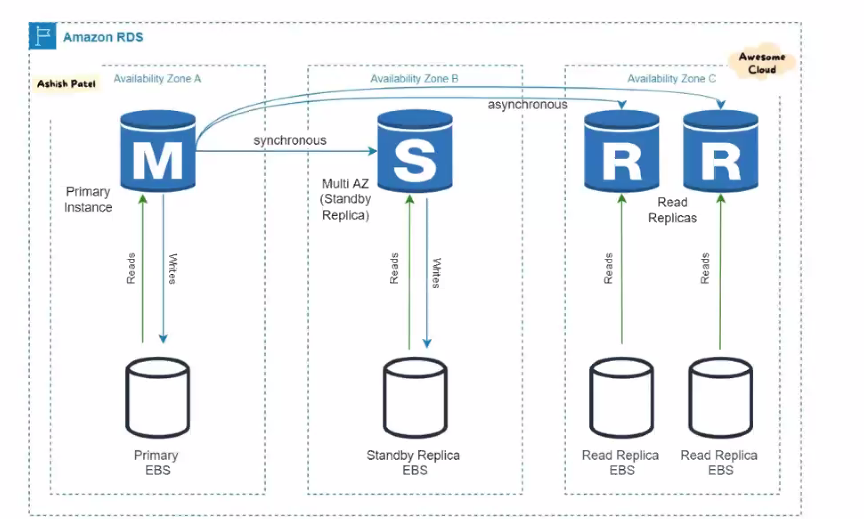
예를 들어 채팅 시스템이 적합하지 않습니다. 동기화는 되지만 느립니다.
오로라 데이터는 ssd에 저장되기 때문에 거의 모든 것이 실시간으로 보장되며, 대역폭(db에 많이 쓰고 읽으면 언젠가는 대역폭 문제가 발생합니다. → 서버가 죽을 수도 있습니다. 양은 훨씬 더 높아야 합니다. rds보다)
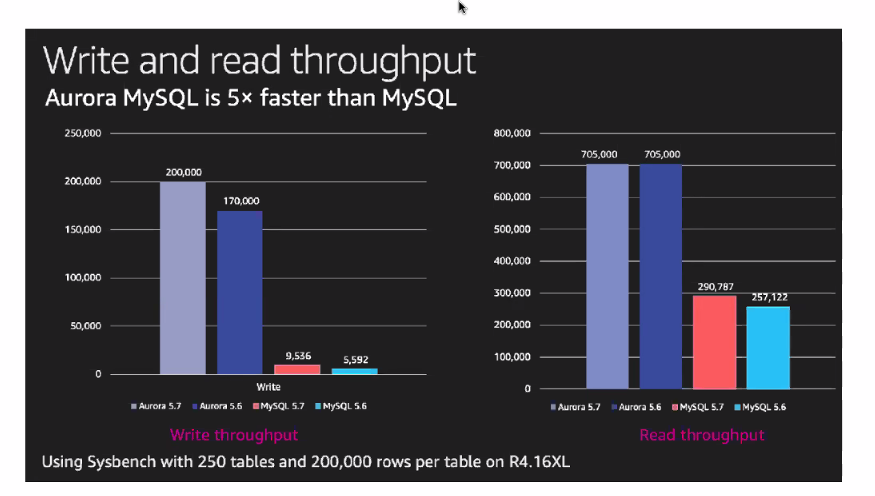
Normal db와 Aurora db 간의 대역폭 비교.
Aurora는 200,000, mysql만 10,000
한 번에 처리할 수 있는 양은 다양합니다.
예전에는 Aurora db를 많이 사용하지 않았는데 요즘은 Aurora db를 자주 사용하려고 합니다.
서버리스 기능은 원래 베타 단계였지만 올해부터 정식 출시돼 많이 활용되고 있는 추세다.
AWS DynamoDB
NoSQL 데이터베이스(키, 값)로 구성됩니다.
기본적으로 서버리스.
유지 관리 비용 없이 사용한 만큼만 비용을 지불하면 됩니다.
- noSQL의 특성상 인덱싱이 없으면 속도가 느리지만 DynamoDB는 그 부분을 해결합니다.
전)
key: userName
Value: {
Address: “”,
Age: “”,
Job: “”
}보조 인덱스 지원은 나이를 키와 값으로 다시 지원합니다.
최대 이점: Lambda(Serverless) Server와의 호환성이 매우 좋습니다.
일반적으로 서버만 켜져 있고 서버 → db 구조: 1 연결, 람다는 여러 연결이 있음 → db 로드가 많이 걸릴 수 있음 5개의 람다로 5개의 연결이 rds로 설정됩니다. 만약 200개의 람다가 있다면 rds로 200번의 연결을 해야하는데 dynamoDB는 http를 통해 연결을 교환하기 때문에 연결 자체를 요구하지도 않고 영향을 주지도 않으니 서버.
AWS 엘라스틱 캐시

Redis의 개념에 더 가깝습니다.
세션 저장소: 인증/로그인 관련 항목을 저장합니다. 많은 회사에서 캐니스터로 사용자를 관리합니다.
Redis에서 AI ML 모델을 업로드하고 사용합니다.
실시간이 높은 작업: 채팅 등
Redis = Elasticache는 99% 동일하게 상상할 수 있습니다.

대기줄
인프라의 핵심 역할.
Kafka는 대기열입니다. 중심 역할.
일반적으로 사용되는 두 가지 대기열이 있습니다.
1. AWS SQS
단순 대기열 서비스
Amazon에서 운영하는 Kafka 서비스
대기열을 두 가지 옵션으로 분리
- 기본 대기열
- 처리량이 무제한입니다. (국경없는 큐잉 서비스)
- 기본 sqs 대기열은 한 번 이상 반환됩니다. : 여러 번 배달될 수도 있는 것 같습니다. 한 번만 도착하면 되는 서비스(예: 입금)는 기본 대기열을 사용하면 안 됩니다.
- Best Effort Order: 순서가 일치하지 않지만 순서를 보장하지는 않습니다.
- 순서대로 따라야 할 서비스 : 은행 : 내 통장 잔고가 1만원이면 입금 순서를 따라야 합니다.
- 적용 예) 사용자 로그를 생성할 때. → 순서를 지키지 않아도 됩니다.
- FIFO 대기열
- 선입선출: 선입선출
- 시퀀스에서 정확히 한 번 처리됩니다.
- 몇 개의 메시지만 동시에 처리할 수 있습니다.
- 정상적인 상황에서는 종종 초당 300개 이상의 메시지이기 때문입니다. 이 경우 fifo를 사용할 수 없습니다.
이메일이나 뉴스레터와 같은 코드를 보내는 경우 대기열에 넣고 하나씩 꺼냅니다. sqs에서 fifo를 사용하십시오. 뉴스레터를 두 번 볼 수 없습니다.
- 장점: 배달 못한 편지 대기열을 지원합니다. 람다가 죽거나 큐에서 메시지가 제대로 전달되지 않거나 메시지가 전송되지 않으면 DLQ(Dead Letter Queue)에서 다시 저장하고 람다를 다시 실행하여 메시지가 정상적으로 전송되기 전에 최대 시도 횟수를 설정합니다. 가 됩니다.
- 이메일이 암호 검색에서 온 것이 아니면 Lambda에서 죽은 것입니다 정보 손실: SQS는 DLQ를 사용하여 각 메시지를 개별적으로 관리할 것을 권장합니다.
2.AWS 키네시스
이는 각 데이터의 중요도보다 대량의 데이터를 처리할 때 중요한 요소입니다.
소카는 카프카를 사용합니다.
Kinesis에는 Kafka와 유사한 기능이 있습니다.
- 모든 크기의 스트리밍 데이터를 저렴한 비용으로 처리할 수 있습니다.
- 적용 예 ) 실시간으로 비디오 및 데이터 스트림을 쉽게 수집, 처리 및 분석
- 데이터 중 사용자 행동 활동을 추적해야 할 때 사용됩니다.

무작위로 파편으로 나뉩니다. 가고 싶은 샤드를 결정할 수 있습니다.
샤드(Shard): 한 번에 많은 양의 데이터가 들어올 때 효과적으로 처리하는 방법을 고민하다 나온 개념.
SQS에는 샤드 개념이 없습니다.

