9-3 TensorFlow로 순환 신경망 만들기
– SimpleRNN 클래스를 사용하여 순환 신경망 생성
1. 반복 신경망에 필요한 클래스 가져오기
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense, SimpleRNN
2. 모델 구축
model = Sequential()
model.add(SimpleRNN(32, input_shape=(100, 100)))
model.add(Dense(1, activation='sigmoid'))
model.summary()
"""
Model: "sequential"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
simple_rnn (SimpleRNN) (None, 32) 4256
dense (Dense) (None, 1) 33
=================================================================
Total params: 4,289
Trainable params: 4,289
Non-trainable params: 0
_________________________________________________________________
"""
3. 모델 컴파일 및 학습
model.compile(optimizer="sgd", loss="binary_crossentropy", metrics=('accuracy'))
history = model.fit(x_train_onehot, y_train, epochs=20, batch_size=32,
validation_data=(x_val_onehot, y_val))
"""
Epoch 1/20
625/625 (==============================) - 16s 23ms/step - loss: 0.7025 - accuracy: 0.5001 - val_loss: 0.6973 - val_accuracy: 0.4982
Epoch 2/20
625/625 (==============================) - 14s 22ms/step - loss: 0.6949 - accuracy: 0.5084 - val_loss: 0.6953 - val_accuracy: 0.5096
Epoch 3/20
625/625 (==============================) - 15s 24ms/step - loss: 0.6927 - accuracy: 0.5174 - val_loss: 0.6944 - val_accuracy: 0.5106
Epoch 4/20
625/625 (==============================) - 14s 22ms/step - loss: 0.6907 - accuracy: 0.5313 - val_loss: 0.6910 - val_accuracy: 0.5268
Epoch 5/20
625/625 (==============================) - 13s 21ms/step - loss: 0.6882 - accuracy: 0.5424 - val_loss: 0.6873 - val_accuracy: 0.5390
Epoch 6/20
625/625 (==============================) - 13s 21ms/step - loss: 0.6814 - accuracy: 0.5609 - val_loss: 0.6827 - val_accuracy: 0.5640
Epoch 7/20
625/625 (==============================) - 13s 22ms/step - loss: 0.6652 - accuracy: 0.5943 - val_loss: 0.6580 - val_accuracy: 0.6044
Epoch 8/20
625/625 (==============================) - 14s 22ms/step - loss: 0.6413 - accuracy: 0.6295 - val_loss: 0.6408 - val_accuracy: 0.6292
Epoch 9/20
625/625 (==============================) - 14s 22ms/step - loss: 0.6258 - accuracy: 0.6507 - val_loss: 0.6381 - val_accuracy: 0.6364
Epoch 10/20
625/625 (==============================) - 14s 22ms/step - loss: 0.6121 - accuracy: 0.6662 - val_loss: 0.6140 - val_accuracy: 0.6718
Epoch 11/20
625/625 (==============================) - 14s 22ms/step - loss: 0.6180 - accuracy: 0.6653 - val_loss: 0.6658 - val_accuracy: 0.5914
Epoch 12/20
625/625 (==============================) - 17s 27ms/step - loss: 0.5998 - accuracy: 0.6801 - val_loss: 0.5900 - val_accuracy: 0.6852
Epoch 13/20
625/625 (==============================) - 14s 22ms/step - loss: 0.5929 - accuracy: 0.6855 - val_loss: 0.5860 - val_accuracy: 0.6956
Epoch 14/20
625/625 (==============================) - 14s 23ms/step - loss: 0.5892 - accuracy: 0.6899 - val_loss: 0.7233 - val_accuracy: 0.6402
Epoch 15/20
625/625 (==============================) - 14s 22ms/step - loss: 0.5837 - accuracy: 0.6950 - val_loss: 0.6422 - val_accuracy: 0.6772
Epoch 16/20
625/625 (==============================) - 13s 22ms/step - loss: 0.5816 - accuracy: 0.6949 - val_loss: 0.6208 - val_accuracy: 0.6650
Epoch 17/20
625/625 (==============================) - 13s 22ms/step - loss: 0.5744 - accuracy: 0.7033 - val_loss: 0.5887 - val_accuracy: 0.7032
Epoch 18/20
625/625 (==============================) - 13s 22ms/step - loss: 0.5741 - accuracy: 0.6999 - val_loss: 0.5705 - val_accuracy: 0.7078
Epoch 19/20
625/625 (==============================) - 13s 21ms/step - loss: 0.5745 - accuracy: 0.6996 - val_loss: 0.5740 - val_accuracy: 0.6996
Epoch 20/20
625/625 (==============================) - 15s 24ms/step - loss: 0.5689 - accuracy: 0.7031 - val_loss: 0.6904 - val_accuracy: 0.6422
"""
4. 교육 및 검증 세트에 대한 손실 및 정확도 플롯 그리기
plt.plot(history.history('loss'))
plt.plot(history.history('val_loss'))
plt.show()

plt.plot(history.history('accuracy'))
plt.plot(history.history('val_accuracy'))
plt.show()
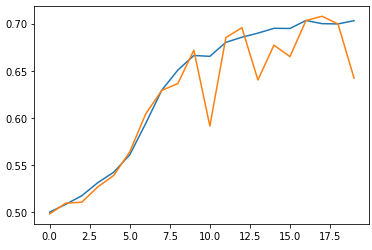
5. 유효성 검사 세트의 정확도 평가
loss, accuracy = model.evaluate(x_val_onehot, y_val, verbose=0)
print(accuracy)
##출력: 0.6421999931335449반응형
– 임베딩 레이어로 순환 신경망 모델의 성능 향상
원-핫 인코딩은 단어 간의 관계를 잘 나타내지 않습니다.
-> Word Embedding은 이 문제를 해결하기 위해 개발되었습니다.

1. 임베딩 클래스 가져오기
from tensorflow.keras.layers import Embedding
2. 학습 데이터 준비
(x_train_all, y_train_all), (x_test, y_test) = imdb.load_data(skip_top=20, num_words=1000)
for i in range(len(x_train_all)):
x_train_all(i) = (w for w in x_train_all(i) if w > 2)
x_train = x_train_all(random_index(:20000))
y_train = y_train_all(random_index(:20000))
x_val = x_train_all(random_index(20000:))
y_val = y_train_all(random_index(20000:))
3. 샘플 길이 조정
maxlen=100
x_train_seq = sequence.pad_sequences(x_train, maxlen=maxlen)
x_val_seq = sequence.pad_sequences(x_val, maxlen=maxlen)
4. 모델 구축
model_ebd = Sequential()
model_ebd.add(Embedding(1000, 32))
model_ebd.add(SimpleRNN(8))
model_ebd.add(Dense(1, activation='sigmoid'))
model_ebd.summary()
"""
Model: "sequential_1"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
embedding (Embedding) (None, None, 32) 32000
simple_rnn_1 (SimpleRNN) (None, 8) 328
dense_1 (Dense) (None, 1) 9
=================================================================
Total params: 32,337
Trainable params: 32,337
Non-trainable params: 0
_________________________________________________________________
"""
5. 모델 컴파일 및 학습
model_ebd.compile(optimizer="adam", loss="binary_crossentropy", metrics=('accuracy'))
history = model_ebd.fit(x_train_seq, y_train, epochs=10, batch_size=32,
validation_data=(x_val_seq, y_val))
"""
Epoch 1/10
625/625 (==============================) - 18s 25ms/step - loss: 0.5244 - accuracy: 0.7362 - val_loss: 0.4544 - val_accuracy: 0.7988
Epoch 2/10
625/625 (==============================) - 17s 27ms/step - loss: 0.4029 - accuracy: 0.8270 - val_loss: 0.4190 - val_accuracy: 0.8150
Epoch 3/10
625/625 (==============================) - 16s 26ms/step - loss: 0.3518 - accuracy: 0.8537 - val_loss: 0.4066 - val_accuracy: 0.8282
Epoch 4/10
625/625 (==============================) - 15s 24ms/step - loss: 0.3223 - accuracy: 0.8698 - val_loss: 0.4144 - val_accuracy: 0.8196
Epoch 5/10
625/625 (==============================) - 15s 24ms/step - loss: 0.3131 - accuracy: 0.8712 - val_loss: 0.4225 - val_accuracy: 0.8230
Epoch 6/10
625/625 (==============================) - 17s 27ms/step - loss: 0.2826 - accuracy: 0.8880 - val_loss: 0.4257 - val_accuracy: 0.8222
Epoch 7/10
625/625 (==============================) - 15s 25ms/step - loss: 0.2597 - accuracy: 0.9000 - val_loss: 0.4343 - val_accuracy: 0.8166
Epoch 8/10
625/625 (==============================) - 15s 25ms/step - loss: 0.2451 - accuracy: 0.9053 - val_loss: 0.5036 - val_accuracy: 0.8006
Epoch 9/10
625/625 (==============================) - 15s 24ms/step - loss: 0.2433 - accuracy: 0.9074 - val_loss: 0.5037 - val_accuracy: 0.8166
Epoch 10/10
625/625 (==============================) - 15s 24ms/step - loss: 0.2230 - accuracy: 0.9161 - val_loss: 0.4878 - val_accuracy: 0.8040
"""
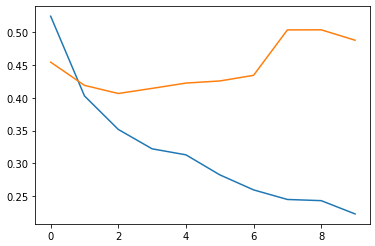
6. 손실 및 정확도 플롯 그리기
plt.plot(history.history('loss'))
plt.plot(history.history('val_loss'))
plt.show()
plt.plot(history.history('accuracy'))
plt.plot(history.history('val_accuracy'))
plt.show()
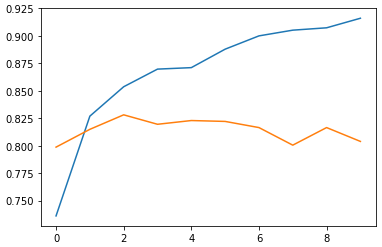
7. 유효성 검사 세트의 정확도 평가
loss, accuracy = model_ebd.evaluate(x_val_seq, y_val, verbose=0)
print(accuracy)
##출력: 0.8040000200271606
※ 내용